TL;DR: GLACE integrates pre-trained global and local encodings, enabling scene coordinate regression to scale to large scenes with only a single small-sized network.
Scene coordinate regression (SCR) methods are a family of visual localization methods that directly regress 2D-3D matches for camera pose estimation. They are effective in small-scale scenes but face significant challenges in large-scale scenes that are further amplified in the absence of ground truth 3D point clouds for supervision. Here, the model can only rely on reprojection constraints and needs to implicitly triangulate the points. The challenges stem from a fundamental dilemma: The network has to be invariant to observations of the same landmark at different viewpoints and lighting conditions, etc., but at the same time discriminate unrelated but similar observations. The latter becomes more relevant and severe in larger scenes. In this work, we tackle this problem by introducing the concept of co-visibility to the network. We propose GLACE, which integrates pre-trained global and local encodings and enables SCR to scale to large scenes with only a single small-sized network. Specifically, we propose a novel feature diffusion technique that implicitly groups the reprojection constraints with co-visibility and avoids overfitting to trivial solutions. Additionally, our position decoder parameterizes the output positions for large-scale scenes more effectively. Without using 3D models or depth maps for supervision, our method achieves state-of-the-art results on large-scale scenes with a low-map-size model. On Cambridge landmarks, with a single model, we achieve 17% lower median position error than Poker, the ensemble variant of the state-of-the-art SCR method ACE. Code is available at: https://github.com/cvg/glace
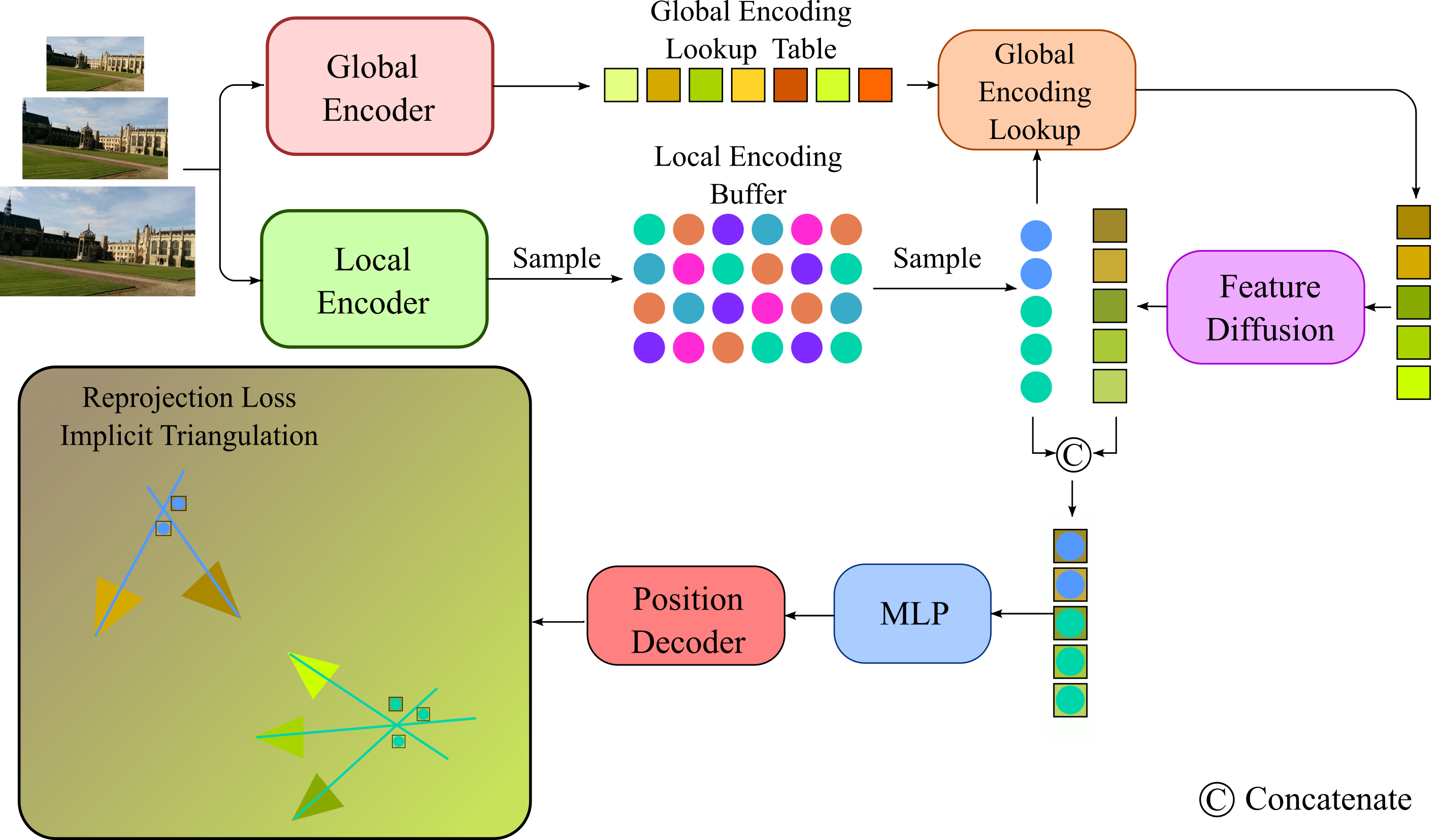
Pipleine of GLACE: Besides the buffer of ACE local encodings, we extract global features of training images with image retrieval model R2Former. During training, we sample a batch of local encodings, look up their global encoding according to their image index and perform feature diffusion by adding Gaussian noise. The global and local encodings are concatenated as input to an MLP head. The output of the MLP is further processed by a position decoder to yield the final coordinate predictions. The global encoding with feature diffusion facilitates the grouping of reprojection constraints, enabling effective implicit triangulation in large-scale scenes.
Simply using a larger network struggles to represent large areas. Existing methods split the scenes into small areas, which is less compact and may lead to suboptimal performance. GLACE allows us to accurately localize in large areas with a single network.

In SCR, each 2D observation independently regresses to a 3D point, the reprojection constraints might seem under-determined. Without Ground truth 3D supervision, why reprojection loss allows the network to learn meaningful 3D reconstruction? We argue that the smoothness prior of the neural network implicitly groups the reprojection constraints of similar input, which triangulate their output points.

However, in large scenes, unrelated yet visually similar observations exist. Robust loss can only mitigate the problem by triangulating only one of the 3D points and treating others as outliers.
Introducing global encoding from a pretrained image retrieval network resolves the global ambiguity. However, different views of the same point have distinct global encodings, leading to overfitting by placing arbitrary points along the ray instead of implicitly triangulating the 3D point.
We propose a feature diffusion technique that simply adds Gaussian noise to the global encoding. This adjusts the strength of the smoothness prior on the global encoding and prevents the network from distinguishing covisible pairs while still resolving global ambiguity in non-covisible pairs. This can also be regarded as a kind of feature metric data augmentation. Unlike K-Means, feature diffusion requires no scene-specific hyperparameters.
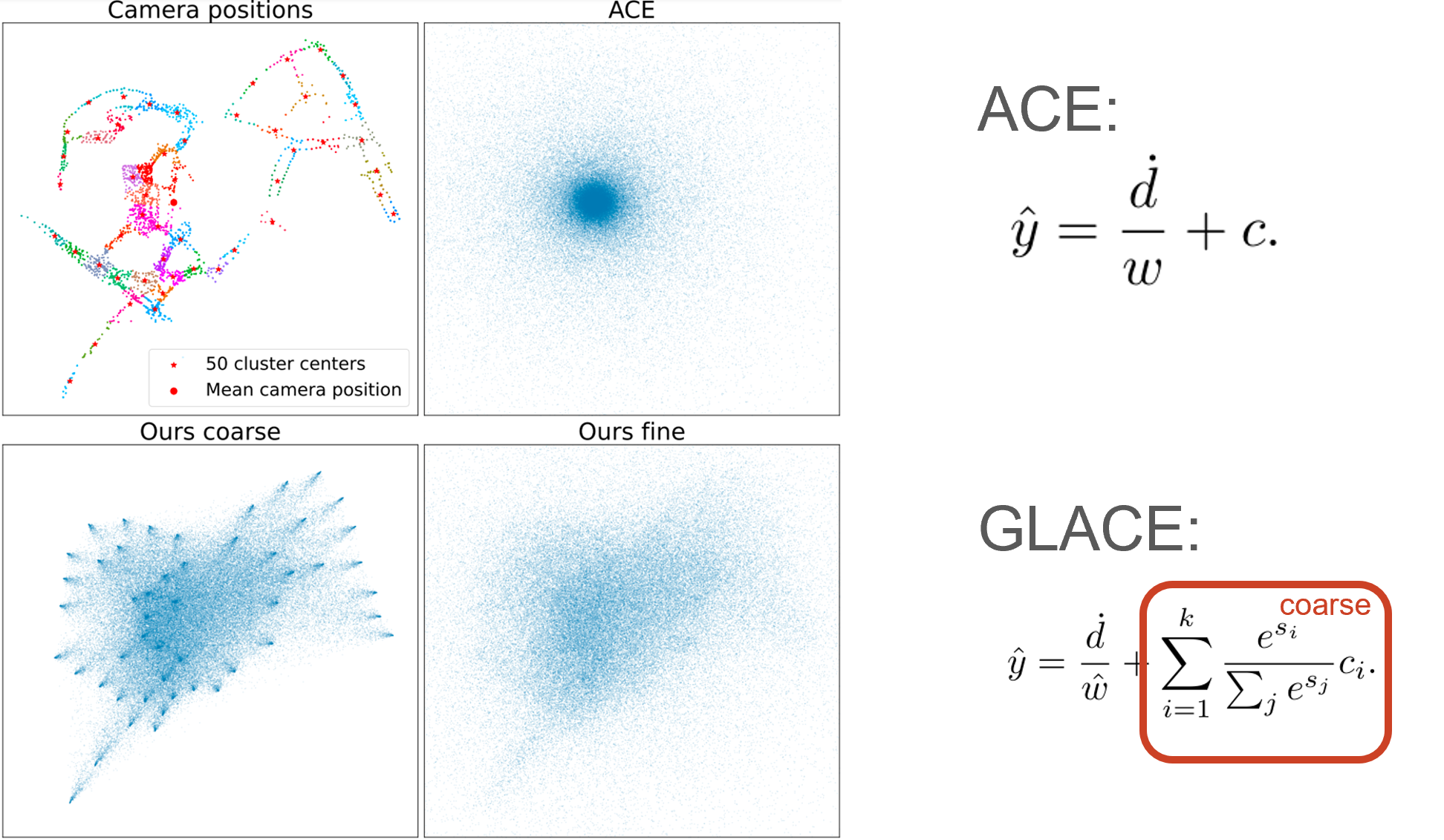
Despite improvements, the network still only well represents the scene near the center. We propose a novel position decoder that replaces the single mean with a weighted average of cluster centers, better parameterizing the multimodal output distribution.
@inproceedings{GLACE2024CVPR,
author = {Fangjinhua Wang and Xudong Jiang and Silvano Galliani and Christoph Vogel and Marc Pollefeys},
title = {GLACE: Global Local Accelerated Coordinate Encoding},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
} GLACE
GLACE